

We have put cameras everywhere. They are in trucks, on factory floors, at construction sites, in hospitals, in stores. For the most part they just sit there recording. Nobody cares until something goes wrong.
But models can now take a live video feed and turn it into language:
- Instead of raw pixels you get something like “a worker climbing scaffolding without a helmet” or “a customer leaves a shelf empty” or “a patient falls near a bed”,
- A second layer then decides what matters: is this just background activity, or is it something that should trigger a task?
- Only when the system decides it crosses that threshold does it flow into Jira, Slack, SAP, Epic, or whatever tool is already running the work.
The reactive paradigm is ending: The only reason we don’t have 1,000x more cameras today is that reviewing footage took forever and cost too much and that bottleneck is about to disappear. This leads to the proactive paradigm: every critical job, every inspection, every high-risk workplace is going to have a camera on it.
AI Cameras Aren’t New
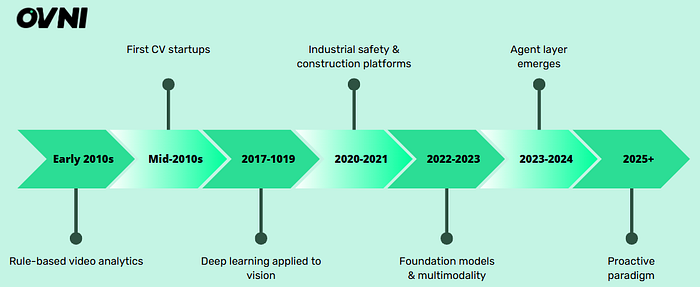
We’ve been trying to make cameras smart for a long time, at least 15y.
In the 2010s, most of the technology was rules-based. A camera could flag “motion detected” by comparing one frame of video to the next. Security teams quicky learned to ignore alerts as a change of light, a passing bird or a branch moving in the wind could set them off.
The next wave (mid 2010s) leaned on classic computer vision. Algorithms like Viola-Jones which had been good enough for quite some time for consumer face detection were brought into CCTV and access control. They could confirm that a human was in the frame of that a face matched a template but the output was limited. Bounding boxes and binary signals didn’t translate well to the complexity of a construction site/warehouse/busy street.
By the early 2020s, startups began to specialize. Some offered helmet detection on construction sites, others pitched traffic analystics for city governments or intrustion detection for factories. They used deep learning models like YOLO and Faster R-CNN, which represented a leap over rules-based methods. But the accuracy was still inconsistent, false positives were piling up and the tools rarely integrated with the systems companies already used to manage work. An alert was still just an alert with no real way to place it in a bigger picture.
What Changed in the Past Two Years
Two big shifts have changed the equation:
- The first shift is almost too obvious to mention: the rise of multimodal language models. Instead of returning a box with a label, today’s systems can watch a stream and generate a sentence: “A worker is on the scaffold without a helmet,” or “An aisle is blocked by a pallet.” Once you have language, you have an interface: something that can be searched, analyzed, or passed into existing tools (like Slack, Jira, SAP...).
- The second is new infrastructure at the edge. Running these models used to mean racks +of GPUs in the cloud and huge bandwidth costs to ship video back and forth but now, cheap GPUs and NPUs are now being embedded directly into cameras and gateways, and they can run transformer-style models in real time (in some industrial settings with latencies under ten milliseconds). The result is a system that not only sees, but can evaluate whether an event actually matters before escalating it.
You can see the shift in the data: Submissions to CVPR, the world’s leading computer vision conference, have grown nearly 3x since 2019, topping 13,000 in 2025.

Those two shifts are the proactive paradigm: cameras can now process an information on the spot, decide if it matters and trigger action in real time.
The First Generation of “Actionable Vision” Companies
Once you accept that cameras can now process and act, you start spotting the pioneers everywhere. On highways, in warehouses, in hospitals, on job sites. This is what the first market map looks like (non exhaustive).

- At the top layer are the vertical apps turning vision into operations. Fleet & field safety (Motive, Samsara, Lytx, Nauto) is the most proven (insurers already see ROI). Industrial EHS (Protex AI, Intenseye, Voxel) is close behind, with compliance and near-miss detection. Construction is harder: slim P&Ls make PPE or site-scan tools tough to justify unless folded into broader stacks like material tracking or waste management (thanks Irénée for the insight).
- The middle layer (Perception & Understanding) is where raw video becomes language. On one side are the foundation models ( OpenAI, Anthropic, Google, Mistral) that proved transformers could watch and describe and the other are the video-native players like Twelve Labs, building APIs that make this capability usable for developers. This layer is still fluid: it’s unclear how much will be dominated by hyperscalers vs. independent enablers.
- The bottom layer (Infrastructure & Enablers) provides the plumbing. New NPUs, FPGAs, and edge GPUs (Groq, Etched, BrainChip, NVIDIA, Qualcomm, Intel, Kinara/NXP) make it possible to run models close to the camera. Real-time infrastructure (LiveKit, Zixi, AWS Panorama, Azure Live Video Analytics) manages the streams. Without this the economics don’t work.
We’ve spent fifteen years trying to make cameras smart but the real breakthrough wasn’t in the lens , it was in the stack around it. i) Multimodal models gave cameras a language, ii) Edge compute made real-time inference cheap and iii) Agent frameworks are (hopefully) about to plug the output into workflows.
The result is a new class of systems: See-Write-Do ==> Cameras that process, decide, and act.
The first generation of companies is already here, let’s see who will build the next ones and in which verticals/layers. :)
Happy to discuss with anyone working on this topic.




